Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to recognize patterns in sequences of data, such as text, speech, or time series data. They are particularly well-suited for tasks where the order of the data is important.
How Do RNNs Work?
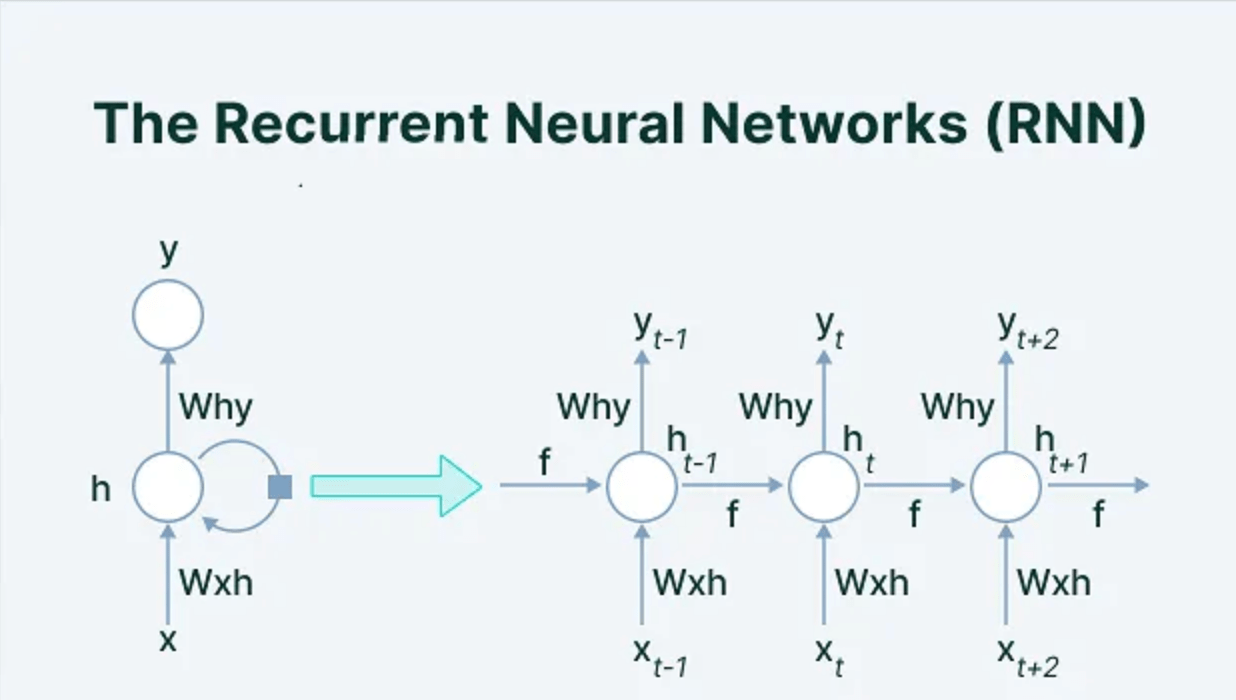
RNNs have an internal memory that allows them to use information from previous inputs to influence the current output. This is achieved through a feedback loop within the network, where the output from the previous step is fed back into the network along with the new input. This structure allows RNNs to maintain context over sequences and make predictions based on both current and past data.Key components of RNNs include:
- Hidden States: These store information about previous inputs.
- Weights: Shared across all time steps, allowing the network to learn temporal patterns.
- Backpropagation Through Time (BPTT): A training algorithm that adjusts the weights by calculating errors at each time step and propagating them backward through the network.
What Can RNNs Do?
RNNs are used in various applications that involve sequential data:
- Language Translation: Converting text from one language to another.
- Natural Language Processing (NLP): Tasks like text generation, sentiment analysis, and named entity recognition.
- Speech Recognition: Converting spoken language into text.
- Time Series Prediction: Forecasting future values based on past data, such as stock prices or weather patterns.
- Image Captioning: Generating descriptive text for images.
Example of RNN Application
A common example of an RNN application is language translation. For instance, Google’s Translate uses RNNs to analyze the structure and context of sentences in one language and generate accurate translations in another language. The RNN processes each word in the input sentence sequentially, maintaining context through its hidden states, and produces the translated sentence as output.
Variants of RNNs
To address some of the limitations of standard RNNs, such as difficulty in learning long-term dependencies, several variants have been developed:
- Long Short-Term Memory (LSTM): Introduced to solve the vanishing gradient problem, LSTMs have special units called cells that can maintain information over long periods. They use gates (input, output, and forget gates) to control the flow of information.
- Gated Recurrent Units (GRUs): Similar to LSTMs but with a simpler architecture, GRUs use reset and update gates to manage the flow of information.
Future of RNNs
While RNNs have been foundational in the development of AI for sequential data, they are increasingly being supplemented or replaced by more advanced models like transformers and large language models (LLMs). These newer models, such as BERT and GPT, are more efficient in handling long-range dependencies and can process data in parallel, leading to faster and more accurate results.However, RNNs still hold value in specific applications where their sequential processing capabilities are advantageous. Future developments may focus on hybrid models that combine the strengths of RNNs with those of transformers and other architectures to create even more powerful AI systems.
RNNs are powerful tools for processing sequential data, with applications ranging from language translation to time series prediction. Despite the rise of newer models, RNNs play a crucial role in AI.
